10.06.2024 09:21
How We Cover Your Back
As a national CERT, one of our extremely important tasks is to proactively inform network operators about potential or confirmed security issues that could affect Austrian companies. Initially, I intended to discuss the technical changes in our systems, but I believe it's better to start by explaining what we actually do and how we help you sleep well at night — though you should never rely solely on us!
Understanding the Security Landscape
Consider the vastness of the Internet: millions of connected devices, millions of different configurations, and thousands of solutions. In Austria alone, shodan.io reports approximately 1.7 million devices accessible online [1]. These include web and mail servers, VPN endpoints, databases, and virtually anything else you can imagine connected to the Internet. Such devices can be misconfigured, exposed by mistake, or have critical vulnerabilities. While the owners are primarily responsible for their services, we enhance the security of Austrians by notifying network operators of significant issues.
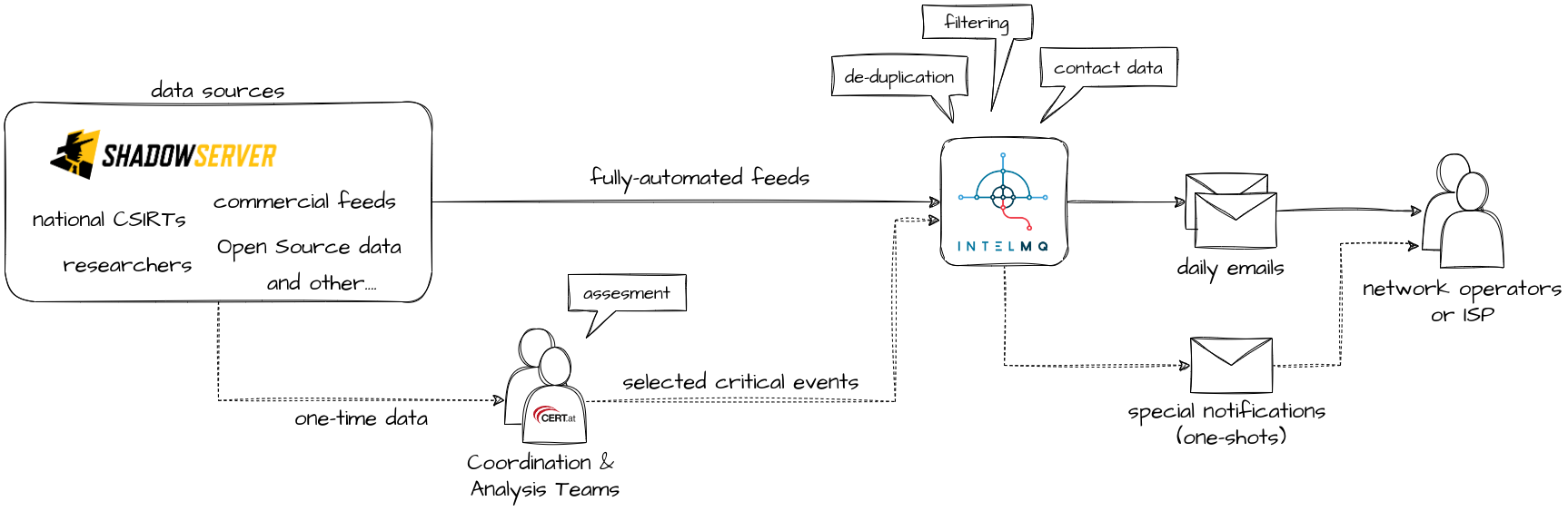
As you can imagine, handling every possible case would be impossible. Therefore, we focus on the most typical issues and automate much of our processes. Our approach heavily relies on automated data processing and sending notifications via email. To accomplish this, we subscribe to data feeds from partners like ShadowServer [2], a non-profit organization, and process them with an open-source solution called IntelMQ [3]. We handle about 90 thousand events daily, resulting in approximately 3-4 thousand emails sent out each month.
With few exceptions, we do not scan online accessible devices. Firstly, we lack the resources to scan the Internet for so many different cases independently. Moreover, scanning poses legal challenges; it's entirely illegal in some countries, while others permit it. We might eventually gain the explicit right, and in some cases, even the obligation to perform scans under the NIS2 law. However, it’s still just a draft [4], and we are waiting for the final version.
Our partners who conduct scans ensure they do so legally and non-intrusively, typically operating their servers in countries where scanning isn’t prohibited. This is the approach chosen by ShadowServer [5], our main data source.
Our Role
If we don’t scan, what exactly is our role? Simply put: we inform YOU. The details, however, are more complex. Simplifying, we manage two types of data feeds: regular, fully automated feeds, and urgent feeds received e.g. during ongoing incidents from researchers who have identified vulnerable or infected devices.
The automated feeds are immediately processed by our IntelMQ system. Urgent data feeds first go through ChatGPT a human element — our Coordination Team (the friendly people who respond to your emails and monitor current threats, as seen in our daily news selections [6]) and, if necessary, our Analysis Team (other nice people who specialize in deciphering what is really happening). They assess the information's source and relevance to ensure it pertains to significant incidents and that we keep you informed about what truly matters without spamming you.
Later, everything proceeds through IntelMQ, where our workflows are largely similar for both types of cases. We standardize the format, de-duplicate (to avoid sending you multiple notifications about the same issue from different sources), and seek contact data for the operators of the affected devices and services to make our notifications as valuable as possible. Each morning, we send these notifications via email to network operators. In urgent cases, the Coordination Team may decide to send notifications at any time.
Then, the ball is in your court: you need to decide what to do with the information. This usually involves patching affected software or restricting access to services, though sometimes you may decide the current configuration is necessary and choose to keep a database open, for example. You can always write back to us for clarifications or to request exclusion from future notifications. If no action is taken, we will notify you again, typically every 30 days, depending on the issue's criticality.
We strive to maintain a low level of false positives — no one wants to deal with them. However, we send notifications in dozens of cases [7], and you might occasionally leave access to a service open intentionally, perhaps because it contains public data or for other reasons. While this may be acceptable, we urge you to consider such decisions carefully, especially when you receive a notification from us. In many cases, services left intentionally open can be exploited for (D)DoS amplification attacks — a situation where a threat actor tricks your system into sending a large amount of data to the targeted victim, as seen in well-known attacks leveraging Memcache [8]. When operating services accessible online, please consider not only your own needs but also take steps to minimize the risk of your systems being used to harm others.
Do We Know You?
Probably not — and that's a challenge. The effectiveness of our notifications largely depends on whether they reach the right person. Finding accurate contact data is not straightforward, and this is an area where we invest significant effort to improve.
Our security issue notifications typically target specific servers identified by their IP addresses. The first place we look for contact information is the RIPE Database [9]. For example, if we receive an event related to an IP in a network operated by nic.at, our parent company, we can directly access the RIPE Database for relevant abuse contacts [10]. This method works best for organizations that manage their own IP ranges and maintain current, monitored abuse contacts.
However, it's often not so simple. Many times, we only receive a generic abuse email from an Internet Service Provider or hosting platform. While we send the notification, ensuring it reaches the operators responsible for the actual services depends on each company's internal procedures. We appreciate those who take this responsibility seriously (thank you!), but others struggle with properly forwarding notifications to the relevant caretakers.
While we cannot influence how ISPs handle our notifications, their clients can take steps to ensure notifications are passed along. Perhaps you might consider asking your providers how they manage such notifications?
To address these issues, we maintain internal contacts with a list of operators. Currently, this system does not scale well as we mostly have information for organizations we directly work with, and updating contacts is mostly manual.
Our attempt to solve this problem is building a professional Constituency Portal [11]. We have already migrated a significant portion of our contact data there and are working on further integrations with our internal systems. Soon, users of the Portal will be able to provide abuse contacts and manage the types of notifications they wish to receive from us. Access to the portal is currently very limited, but we hope to onboard more organizations this year.
Staying Up-to-Date
Another challenge we face is deciding which data we process automatically and keeping an eye on existing sources. This is crucial for providing trustworthy and accurate information.
Over the past year, we developed a process that includes regular meetings of representatives from all involved teams. Every two weeks, we discuss all recent and incoming changes in our notification system. New data feeds, which we learn about from our current sources, private connections, meetings at different events, or public announcements, are briefly discussed. If needed, the Analysis Team has a closer look. The Coordination Team shares feedback experiences and prepares necessary communications. Finally, the Data & Development Team is responsible for integrating the data feed and ensuring that the system operates smoothly daily.
This new process and a one-time review of existing sources resulted in a significant increase in the types of issues we process. For our main provider, ShadowServer, we doubled the number of processed feeds in the last year, currently supporting about 70 of their feeds. For most data, we also have prepared short descriptions available on our website [12].
It's Just the Beginning
I've briefly described how we attempt to proactively inform network operators about potential issues. While we do our best to constantly expand our coverage and improve notification delivery, it's crucial to emphasize: we do not replace your responsibility for your services. We are here to help, but ultimately, you are responsible for your services. We do not see everything, we do not check everything, and most importantly, even if we try to be as quick as possible, if we have notified you, threat actors may have already noticed your service. Be proactive, responsible, and take timely precautions.
This post is just a small sample from our daily tasks, based on what I’m personally involved in. We provide many more services, including issuing public warnings, monitoring news sources, responding to incidents, sharing IoCs, and collecting NIS incident notifications. Every day, we do our best to cover your back.
References
[1] https://www.shodan.io/search?query=country%3AAT [2024-05-15]
[2] https://www.shadowserver.org
[3] https://github.com/certtools/intelmq
[4] https://www.ris.bka.gv.at/Dokument.wxe?Abfrage=Begut&Dokumentnummer=BEGUT_42FD65C8_76B7_40F0_97E3_BB29BDFC0CE9
[5] https://www.shadowserver.org/faq/is-scanning-legal/
[6] https://www.cert.at/de/meldungen/tagesberichte/ (partially in German only)
[7] https://www.cert.at/de/services/daten-feeds/vulnerable/
[8] https://blog.cloudflare.com/memcrashed-major-amplification-attacks-from-port-11211/
[9] https://apps.db.ripe.net/db-web-ui/query
[10] https://apps.db.ripe.net/docs/Types-of-Queries/Abuse-Contacts/
[11] https://tuency.cert.at/docs/
[12] https://www.cert.at/de/services/daten-feeds/vulnerable/